
Davide Murari is a PhD student at the Norwegian University of Science and Technology, in the group of Differential equations and Numerical Analysis (DNA).
Ferdia Sherry is a postdoctoral research associate in the Cambridge Image Analysis (CIA) group at DAMTP, at the University of Cambridge.


In a long-standing collaboration between the DNA group at NTNU and the CIA group at the University of Cambridge, we have been doing research in the field of structure-preserving deep learning (Celledoni et al., 2021). A major topic within this field is concerned with drawing connections between dynamical systems and neural networks. In this blog post, we discuss this topic, focusing on its use in designing stable neural networks.
ODE-based approaches to designing stable neural networks
Neural networks have attracted much interest because of their significant success in multiple tasks, especially when dealing with high-dimensional problems. This success is mainly based on experimental evidence, while the theoretical understanding of these techniques is still catching up. In the last years, there have been multiple attempts at mathematically explaining why neural networks work, including one known as the dynamical systems perspective on neural networks.
The main idea behind this approach, first introduced in (E, 2017), is to interpret the layers of neural networks as discrete approximations to the solution of an ordinary differential equation. This procedure allows us to borrow from the well-developed fields of dynamical systems and numerical analysis to design new neural network architectures or interpret existing ones. A popular philosophy that is closely related, but is slightly different, is the one of Neural ODEs, started by (Chen et al., 2018). Here, instead of designing a neural network as the discretisation of a differential equation, learning the network weights is seen as an optimal control problem, where the purpose is to minimise a cost function subject to the satisfaction of a parametric ordinary differential equation. In what follows, we will be focused on the first approach, noting that similar ideas may be applicable in the Neural ODE setting, too.
Classification problems provide a simple example to clarify this interpretation of neural networks. In this case, the goal is to assign labels to unlabelled data points. One can think of the data points as initial conditions of a parametrised dynamical system, whose parameters are optimised so that, at a final time, the inputs are transported into a configuration where they are linearly separable into classes. The following GIF shows such an idea in a 2D binary classification problem, where the dynamical system driving the points is learned by solving an optimisation problem, i.e. by training the neural network.

Following this mathematical interpretation of neural networks, we have designed neural networks based on discretising gradient flows of suitable parametric convex potentials. This has allowed us to get image denoisers with provable convergence guarantees and image classifiers with reduced sensitivity to input perturbations. We expand on these two applications in the following sections of the post.
Applications to deep-learning-based image processing methods with provable guarantees
As in many other fields, deep learning (DL) methods have risen to prominence in image processing recently: the great flexibility of these methods, combined with large amounts of available data, allows them to be used very effectively to encode prior information. This is of particular importance in ill-posed inverse problems (such as the reconstruction problems for magnetic resonance imaging or computed tomography), where the goal is to recover an underlying image from noisy measurements, but the naïve inversion is not well defined or is unstable. By appropriately incorporating prior information, we can regularise the inversion process. A well-known way of doing this is called Plug-and-Play (Venkatakrishnan et al., 2013), where a pre-trained Gaussian denoiser is combined with the measurement model in an iterative process to obtain reconstructions.

An illustration of the convergence/divergence of repeated applications of DL denoisers to a given input image. DnCNN is a DL denoiser with high denoising performance but no guarantees (resulting in divergence), while ΓEuler is a DL denoiser based on robust dynamical systems, with high denoising performance and provable guarantees (resulting in convergence).
A fundamental issue that arises when applying unconstrained neural network denoisers in this setting is that we can not guarantee the convergence of this iterative process, which makes it hard to trust this approach in safety-critical applications such as medical imaging. By designing neural networks based on carefully discretised gradient flows in learnable convex potentials, we find that it is possible to obtain learned denoisers with provable convergence guarantees, that nonetheless perform on par with unconstrained, high-performing learned denoisers (Sherry et al., 2023).
Applications to adversarial robustness of classifiers for image or graph data
Besides the work on robust neural networks in image processing that we discussed above, there is a considerable amount of work studying the vulnerability of neural networks to adversarial attacks. It has been shown that state-of-the-art neural network image classifiers are susceptible to adversarial perturbations (Goodfellow et al., 2014): imperceptible (to humans) perturbations that can be added to input images to fool the trained classifier. In the face of this issue, there have been many attempts to improve the robustness of neural network classifiers and one such approach proceeds by designing neural network architectures based on dynamical systems that have desirable robustness properties (Celledoni et al., 2023). Using neural network layers based on contractive dynamical systems, it was demonstrated that robustness can be significantly increased in comparison to similar, but unconstrained, neural network architectures. Furthermore, the dynamical systems perspective was used to show that contractive and expansive layers can be combined in one architecture to get similar robustness gains, while improving expressivity.
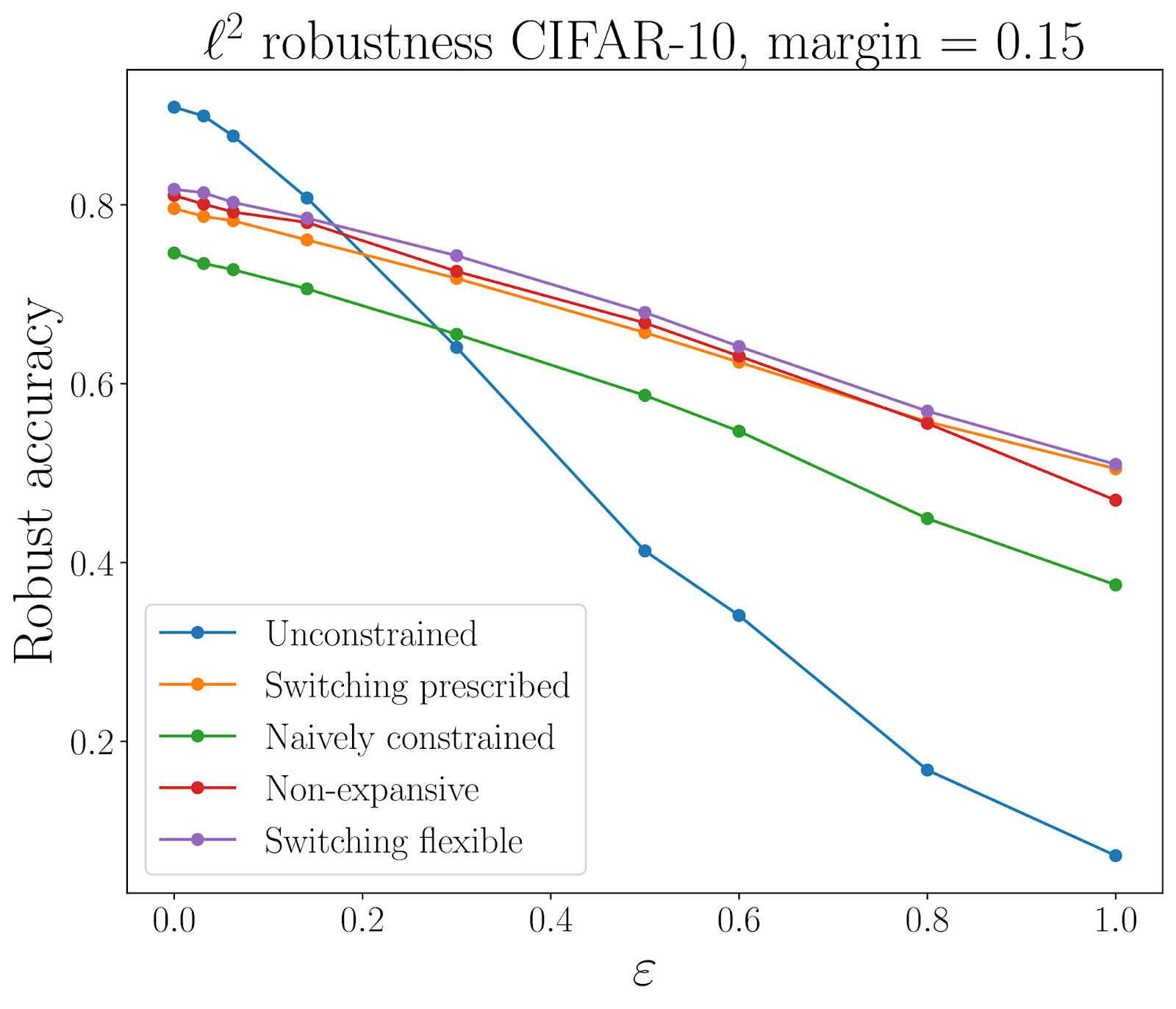
By using dynamical systems-based neural networks, we can improve the robustness of image classifiers, as demonstrated here on the CIFAR-10 dataset. On the horizontal axis, the allowed perturbation size is given, while on the vertical axis, we see the accuracy of the image classifier at the given perturbation size. Image taken from (Celledoni et al., 2023).
Moving beyond image data to other data types brings interesting additional challenges when designing adversarially robust neural networks. As an example, graphs can carry information both in the form of node features and of connectivity between nodes (and an adversary may be able to attack both, by adding or removing nodes and edges or changing the node features), and simple Euclidean metrics are not appropriate as measures of the size of the corresponding attacks. The first point makes it necessary to jointly process the node features and underlying adjacency matrix, while the second point tells us that we should consider non-Euclidean metrics for which the underlying dynamical systems under consideration are robust. By making use of the non-Euclidean contraction theory from (Bullo, 2022), we find that we can design dynamical systems-based graph neural networks that jointly process the node features and connectivity of a graph, giving improved robustness to many common graph adversarial attacks (Eliasof et al., 2023). This field of research continues to be highly active, with open questions remaining, such as how to close the gap in clean performance (i.e. on data that has not been attacked) between unconstrained and robust networks, and how to ensure the computational scalability of these robust networks and their training methods.
References
- Bullo, F. (2022). Contraction Theory for Dynamical Systems. Francesco Bullo. https://fbullo.github.io/ctds/
- Celledoni, E., Ehrhardt, M. J., Etmann, C., McLachlan, R. I., Owren, B., Schönlieb, C.-B., & Sherry, F. (2021). Structure-preserving deep learning. European Journal of Applied Mathematics, 32(5), 888-936. https://doi.org/10.1017/S0956792521000139
- Celledoni, E., Murari, D., Owren, B., Schönlieb, C.-B., & Sherry, F. (2023). Dynamical Systems-Based Neural Networks. SIAM Journal on Scientific Computing, 45(6), A3071-A3094. https://doi.org/10.1137/22M1527337
- Chen, R. T., Rubanova, Y., Bettencourt, J., & Duvenaud, D. K. (2018). Neural ordinary differential equations. Advances in Neural Information Processing Systems, 31. https://dl.acm.org/doi/10.5555/3327757.3327764
- E, W. (2017). A proposal on machine learning via dynamical systems. Communications in Mathematics and Statistics, 1(5), 1-11. https://doi.org/10.1007/s40304-017-0103-z
- Eliasof, M., Murari, D., Sherry, F., & Schönlieb, C.-B. (2023). Contractive Systems Improve Graph Neural Networks Against Adversarial Attacks. arXiv:2311.06942. https://arxiv.org/abs/2311.06942
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and Harnessing Adversarial Examples. arXiv:1412.6572. https://arxiv.org/abs/1412.6572
- Sherry, F., Celledoni, E., Ehrhardt, M. J., Murari, D., Owren, B., & Schönlieb, C.-B. (2023). Designing Stable Neural Networks using Convex Analysis and ODEs. arXiv:2306.17332. https://arxiv.org/abs/2306.17332
- Venkatakrishnan, S. V., Bouman, C. A., & Wohlberg, B. (2013). Plug-and-Play priors for model based reconstruction. 2013 IEEE Global Conference on Signal and Information Processing, 945-948. https://doi.org/10.1109/GlobalSIP.2013.6737048