
Our current research with the Weave-Unisono project concentrates on the new pre-processing algorithms for non-Gaussian cyclostationary models segmentation.
In many real-world systems, data exhibit both regular patterns and irregular disturbances. A particularly important class of such processes is cyclostationary signals, whose statistical properties repeat over time. These signals arise naturally in engineering, physics, medicine, and finance. However, classical approaches typically assume Gaussian behavior, which is often violated in practice due to the presence of impulsive events. Many real-world signals exhibit non-Gaussian, impulsive behavior, e.g.: vibration signals in condition monitoring (mechanical systems), abdominal recordings, combining cardiac, respiratory, and gastrointestinal signals, heart rate variability. Figure 1 illustrates the example signals for which we can observe sudden spikes and bursts that clearly deviate from Gaussian assumptions.

Cyclostationary processes
Cyclostationary processes extend stationary models by allowing their statistical properties to vary periodically. Formally, a process is cyclostationary if its mean and autocovariance repeat with a fixed period 

where 

In many classical settings,

where 



: purely Gaussian behavior,
- small
: rare impulses,
- large
This formulation allows for a smooth transition between Gaussian and highly non-Gaussian regimes, reflecting real signal characteristics.
Time-varying impulsiveness
In practical applications, the level of impulsiveness is not constant. Systems evolve over time, leading to changes in the statistical structure of the signal. In our analysis, we assume that the distribution of the background noise varies over time, with 


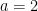
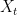

This figure clearly shows how the signal alternates between regimes of low and high impulsiveness, making the detection of structural changes a non-trivial task.

What’s new?
The research addresses structural change detection (distributional shifts) in cyclostationary models, motivated by signals transitioning from Gaussian to impulsive noise. Two segmentation approaches are proposed: HMM (two variants) and distribution-distance-based methods (MIDAST).
The change point detection problem
Problem: Detecting structural changes in such signals is difficult due to:
- temporal dependence (autoregressive structure),
- periodic behavior,
- non-Gaussian and evolving distributions.
Classical change point detection methods typically assume independence and Gaussianity, which limits their applicability.
Proposed solution: The application of parametric methods, predicated on prior knowledge of the underlying data-generative cyclostationary model. Alternatively, statistical methods may be employed to analyze noise variability (in the latter case, preliminary data processing is required).
Approach 1: Hidden Markov Models (HMMs)
We assume that the changes of the parameter 
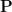






- (HMM
): The PAR model structure is taken into account in the estimation procedure and no initial detection of periodicity is required.
- (HMM
): The second version is designed for the segmentation of the residuals series. In this case, an additional preliminary step is required.
This enables segmentation of the signal into regions with distinct statistical properties. Importantly, this method can be applied directly to the observed data.
Approach 2: Distributional Distances
An alternative approach is based on comparing distances between distributions across segments. It is univariate veersion of MIDAST [2]. If two neighboring segments differ significantly in terms of distributional distances, a change point is detected. Here, we use two versions of this method that utilize the following statistical tests for equality of distributions:
- (
): the distributional distances-based procedure that use two-sample Epps–Singleton test for equality of distributions [3],
- (
): the distributional distances-based procedure that use two-sample Cramér–von Mises test for equality of distributions [4].
These tests capture different aspects of distributional differences, from global shape to higher-order properties. While effective, this approach typically requires preprocessing to remove periodic dependencies.
Comparison of methods
The performance of different methods can be evaluated using simulation studies. Figure 3 presents the normalized error of change point estimation under various scenarios. In the simulations, we assume a scenario involving a data sequence of length 
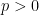

HMM


[1] A. P. Dempster, N. M. Laird, and D. B. Rubin. “Maximum Likelihood from Incomplete Data via the EM Algorithm”. Journal of the Royal Statistical Society. Series B (Methodological) 39 (1977), 1–38.
[2] J. Witulska et al. “Identifying the temporal distribution structure in multivariate data for time-series segmentation based on two-sample test”. Information Fusion 125 (2026), 103445.
[3] T. Wepps and K.J. Singleton. “An omnibus test for the two-sample problem using the empirical characteristic function”. Journal of Statistical Computation and Simulation 26 (1986), 177–203.
[4] T. Wanderson. “On the distribution of the two-sample Cramer-von Mises criterion”. Annals of Mathematical Statistics (1962), 1148–1159.
By Agnieszka Wylomańska and Justyna Witulska (Wrocław University of Science and Technology).