In today’s world, data in graph and tabular form are being generated at astonishing rates, with algorithms for machine learning (ML) and data mining (DM) applied to such data establishing themselves as drivers of modern society. The field of graph embedding is concerned with bridging the “two worlds” of graph data (represented by nodes and edges) and tabular data (represented by rows and columns) by providing means for mapping graphs to tabular data sets, thus unlocking the use of a wide range of tabular ML and DM techniques on graphs.
Graph embedding enjoys increased popularity in recent years, with a plethora of new methods being proposed. However, none of them address the dimensionality (number of columns) of the new data space with any sort of depth, which is surprising since it is widely known that dimensionalities greater than 10-15 can lead to adverse effects on tabular ML and DM methods, collectively termed the “curse of dimensionality.”
This project investigates the impact of the curse of dimensionality on graph-embedding methods by using two well-studied artefacts of high-dimensional tabular data: (1) hubness (highly connected nodes in nearest-neighbor graphs obtained from tabular data) and (2) local intrinsic dimensionality (LID – number of dimensions needed to express all information near a data point). After evaluating existing graph-embedding methods w.r.t. hubness and LID, we will design new methods that take those factors into account. We expect the project to produce graph-embedding methods substantially more accurate than the state-of-the-art in two aspects: (1) graph reconstruction in the new space, and (2) success of applications of the produced tabular data sets to the tasks of classification, clustering, similarity search and link prediction.
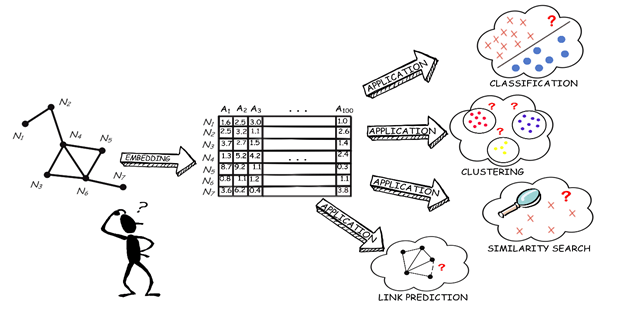
The proposed methods will introduce graph embedding to many domains where such solutions were simply not good enough so far, first and foremost in scientific research (e.g. bioinformatics, sociology, economics), as well as technology and industry (e.g. predictive analysis of energy-supply, telecommunication and transport networks), education (e.g. analytics of data from e-learning systems), and society in general (e.g. improved/new services of social networking sites, or even new kinds of social networking not possible before).
The project will last two years with an allocated budget of over 120 thousand Euro. The project team consists of a blend of seasoned and young researchers from the Faculty of Sciences in Novi Sad, with emphasis of early career researchers. All participants are employed at the Department of Mathematics and Informatics, at the Chair of Computer Science and Chair of Information Technologies and Systems. The principal investigator is Dr Miloš Radovanović, and team members are Dr Mirjana Ivanović, Dr Vladimir Kurbalija, Dr Miloš Savić, Dr Brankica Bratić, Nemanja Milošević, Dušica Knežević and Aleksandar Tomčić.
Acronym: GRASP
Funding: Science Fund of the Republic of Serbia
Funding Program: Program for Development of Projects in the Field of Artificial Intelligence
Subprogram: Fundamental Research
Research field of the Project: Machine Learning
Participating Scientific and Research Organizations (SROs): University of Novi Sad, Faculty of Sciences (UNSPMF)
Principal Investigator (PI): Miloš Radovanović
Start: 1.9.2020.
Duration: 24 months
Project Web site: https://graphsinspace.net/


